A harsh headline, I know. I stand by my opinion though and do not consider it to be clickbait. Maybe I will concede to the fact that the platform itself might not suck but the methods being used to track rankings in most tools is erroneous. Plain and simple. The best keyword rank tracker needs to evolve in order to survive in the current local SEO climate, post Possum.
For any of you that do client work, how many times in the past year or two have you been on a call with the manager of the account or the owner(s) and have people saying things like, “this is #2 for me!” or “I am not even seeing it in the three pack!”?
Yea, I would be willing to bet you are familiar with conversations like that.
The fact of the matter is, the proximity of the person performing the search has become such an impactful ranking factor that it has turned the SERPs upside down for a lot of local marketers and business owners alike.
This has also made conventional rank tracking a thing of the past. If you have been paying close attention, since the Possum update, you will know rank trackers are all over the place.
Theoretically, this is can be traced back to a very specific Google patent that details using the distance between the user and the location of the business. Here is a direct quote from the patent,
Methods and apparatus related to associating a quality measure with a given location. For example, an anticipated distance value for a given location may be identified that is indicative of anticipated time and/or distance to reach the given location. At least one actual distance may be identified that is indicative of actual time for the one or more members to reach the given location. In some implementations, the anticipated/actual distance values may include one or more distributions. A quality measure is then determined based on a comparison of the anticipated distance value and the identified actual distance value. The quality measure is associated with the given location. The quality measure may be further based on additional factors.
I do think everyone should take a few moments to read through the full patent, and I do not want to oversimplify it, but this drawing helps sum up how they want their ecosystem to handle proximity in case you just want an overview.
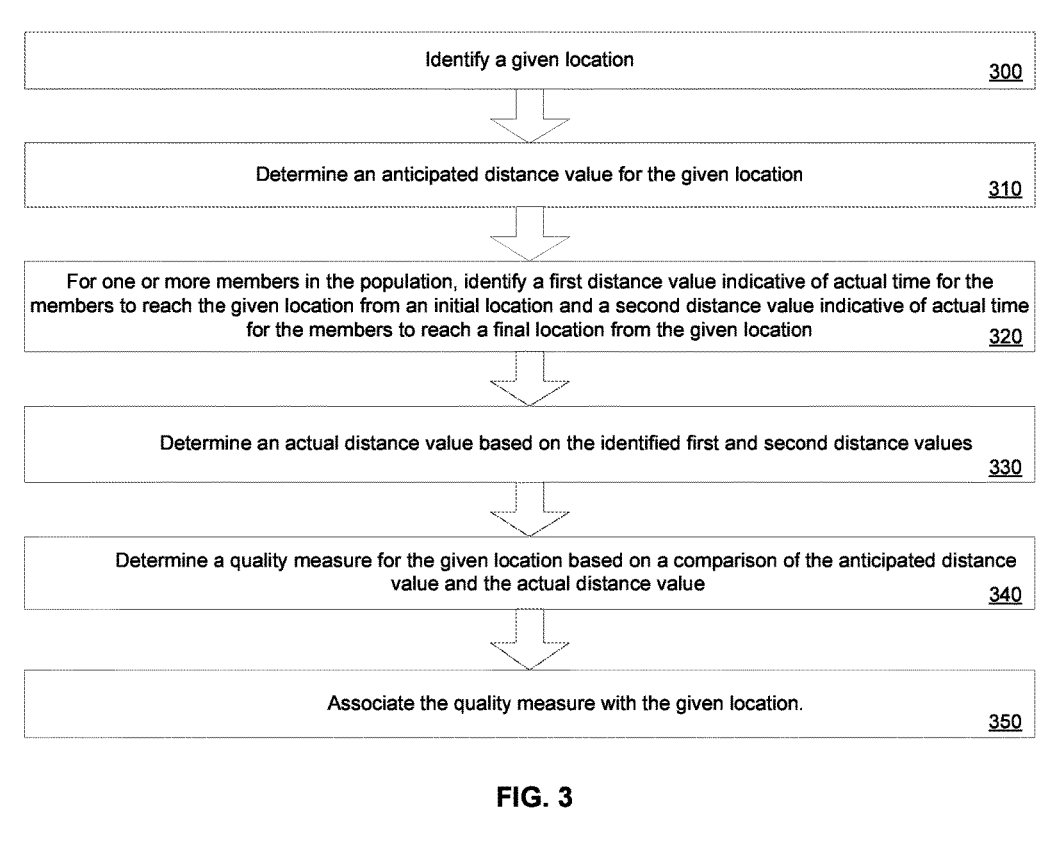
I hyperlinked the above image to the “patent images” PDF so you can have a look for yourself.
So, now we know that Google is serving results to users with proximity being an extremely impactful ranking factor. Theoretically, this patent could help explain what exactly The Big G is up to. So, since rank trackers are all discombobulated, how do we fix this?
Great question. Let’s deep dive.
First, we need to somewhat understand what Google’s process is when determining what results to serve its users. Google looks at a few main things with respect to proximity. It looks at these things with the intent of building a prediction model. I will try not to bore you with extraneous technical verbiage, but I will link to some heavier reading in case you want to dig deeper into some of the testings that have been done on Google’s predictive model for their maps platform.

When Google tries to determine the proximity from the user to the locations that meet their user intent, it relies on the accuracy of the synchronization between the true location data of the business and where they determine the device to use that is performing the search.
As you can see from the image above, an experiment conducted on measuring the accuracy of Google’s process to determine true location, Google experiences “misses” and “hits” which boil down to inaccuracies in getting this data perfect. What this means is Google is going to essentially serve different results based on factors you cannot control.
This can come from phone configurations. Notice the difference in errors between the different networks and whether the search is on Wi-fi or GPS in the image below.

There are also accuracy issues associated with the environment.

Notice how you being in an urban or rural setting as well as the phone configs affect the accuracy of the results. Finally, we need to consider the action in which the user is engaged during the search.

As you can see, again, there are hits and misses that fluctuate based on the way in which the user is traveling. I do not say this to put a damper on your confidence in Google, obviously, they suck at some stuff, but they have some really impressive geospatial engineering in place.
The point from all of this is that we know Google is using proximity as one of the most powerful factors to determine which results to display, and even if this test pulled back some anomalous error reports, you can still see how easy it is for no two searches to necessarily be handled the same in terms of which results to display, or at least if the results are similar we can assume that it is other GMB ranking factors that are causing the results to be parodied. (Theoretically)
Even if I am being overly pessimistic by saying “no two searches are alike” (which I concede could be totally wrong) we can assume that when you start factoring in the hundreds of times your keywords are queried from around the area and with people on different devices or using different networks, there are going to compounding consistencies that could easily lead to a simple rank tracking scraper bringing back bad or inconsistent data.
How do we do better?
That is a great question. We are not going to ever see a 100% foolproof system because we are not going to be able to account for all of the variables that Google looks at to determine proximity. What we can do is use a few different methods to at least have some impressive benchmarks.

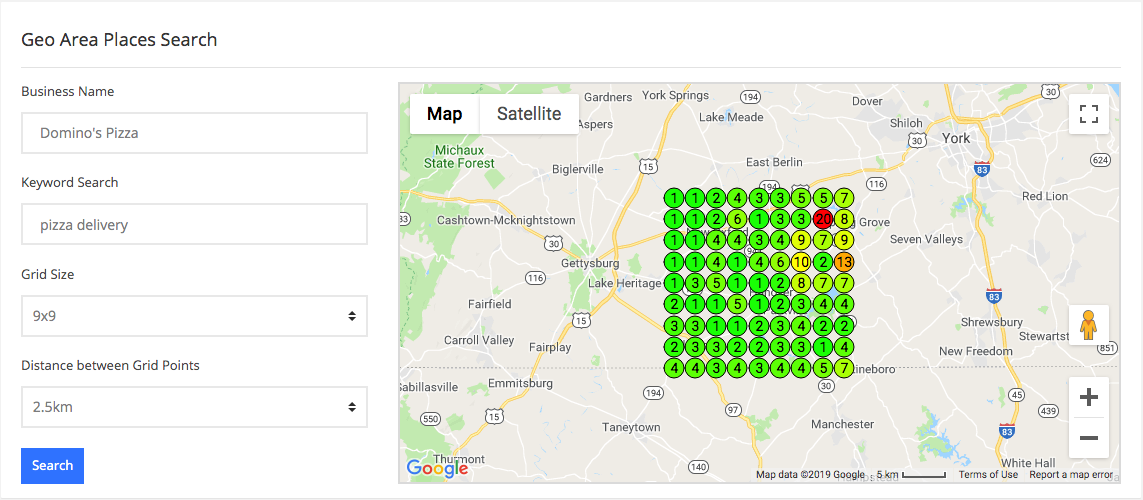
We are in the process of updating this but from a glance, you can see we actually have two rank tracking methods right here in this dashboard. The first is a typical rank tracker. The results are derived from scraping Google. Again, the results are not going to be perfect, but it does help establish a benchmark.
On the right side, we are using a simple Geohash to modify the geodata in our browser and essentially put us in the location in which we are tracking our keywords. Google Maps have recently added some Javascript to rectify this option and revert the browser back to its actual location, so we are also injecting the ad test command into the URL so we can keep the location constant.
Using the UULE parameter to geolocalize our result, the Geohash, and then locking it into place to avoid Google Maps reverting the location back using the &adtest=on is not perfect by any means. You miss the proximity bit because this tactic puts you at the static hash location, but it is a common strategy. You will find a lot of local rank tracking tools using this strategy.
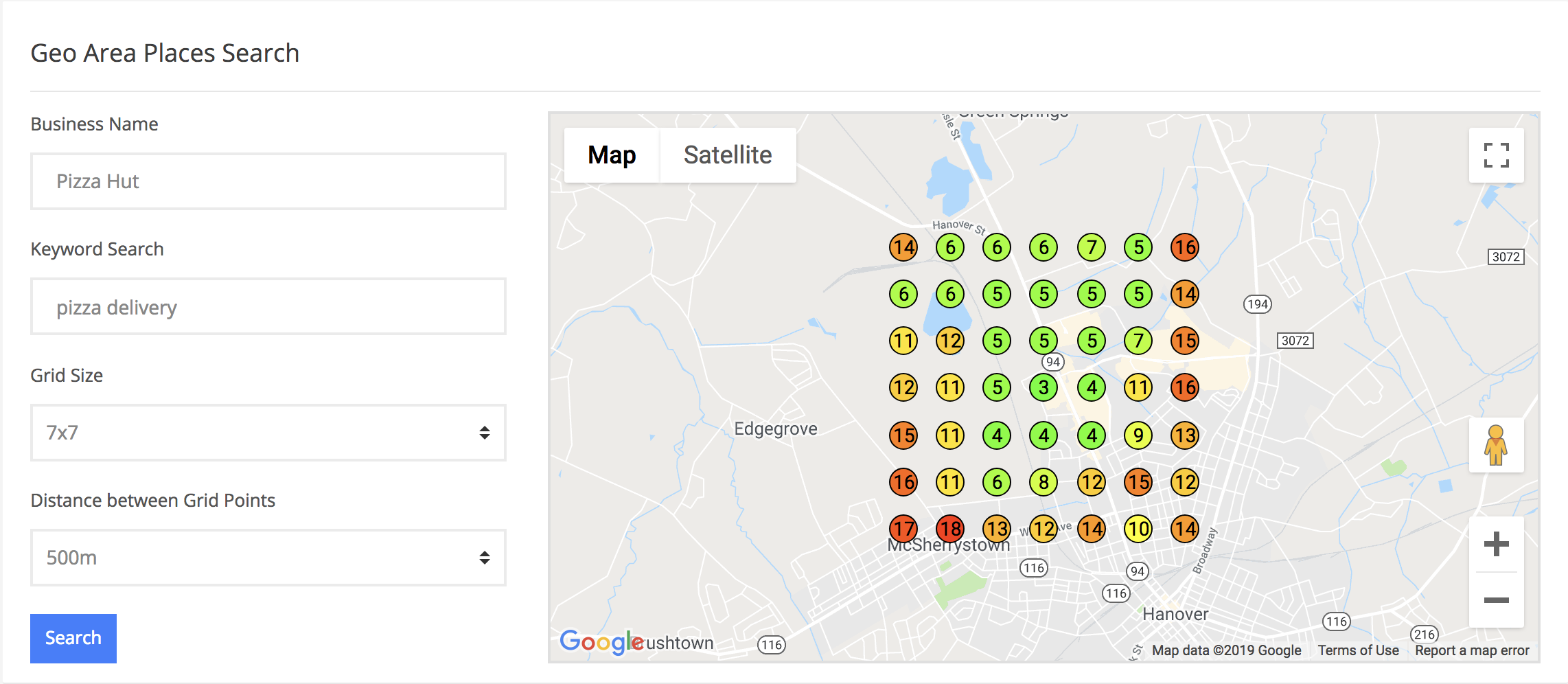
Another way to skin this cat (Who the heck skins cats? Is that the correct term that people say? Sheesh…) Anywho…
We can tap directly into the GMB API and populate data all over a city. This obviously is not taking into consideration the phone configurations or the actions that the user is taking whilst performing the query, but it is darn good data. Some people are becoming militant about data pulled in this way, proclaiming it is not accurate.
I will say, that in our testing, it provided really solid data. Nothing is going to be “perfect”. A rank tracker that works 100% of the time for everyone in an area is not on the menu. It is not going to happen. The best thing we can do is leverage a few different sources to gather benchmarks and show the increase in insights, phone calls. visibility, etc.
NOTE: The geogrid is designed to use base level keywords without a geo modifier because the geo is already pulled from the locations pin. Keep that in mind if you decide to jump over to our GEO Grid Rank Tracker and start checking out maps rankings.
We are using a few other methods to pull in rankings with great results. I will add to this post and update you guys on what they are as we test more and bake them into Local Viking. If you have any questions or comments please do let me know.